
In a stunning development that has sent shockwaves through the semiconductor industry, major RAM and memory chip manufacturers saw their stocks tumble sharply this week following Google’s announcement of TurboQuant—a revolutionary AI compression algorithm that slashes memory usage for large language models (LLMs) by a factor of 6 while boosting inference speed by up to 8x, all without any loss in accuracy.
The news, unveiled by Google Research on March 24-25, 2026, has investors scrambling, with shares of industry leaders like Samsung Electronics, SK Hynix, Micron Technology, Western Digital, and SanDisk dropping between 4% and 8% in trading sessions across Seoul and U.S. markets. Analysts estimate immediate market value losses in the hundreds of millions of dollars, with broader concerns now mounting about potential quarterly earnings hits and downward pressure on RAM prices in the coming months.
The TurboQuant Revolution: How Google Cracked AI’s Memory Bottleneck
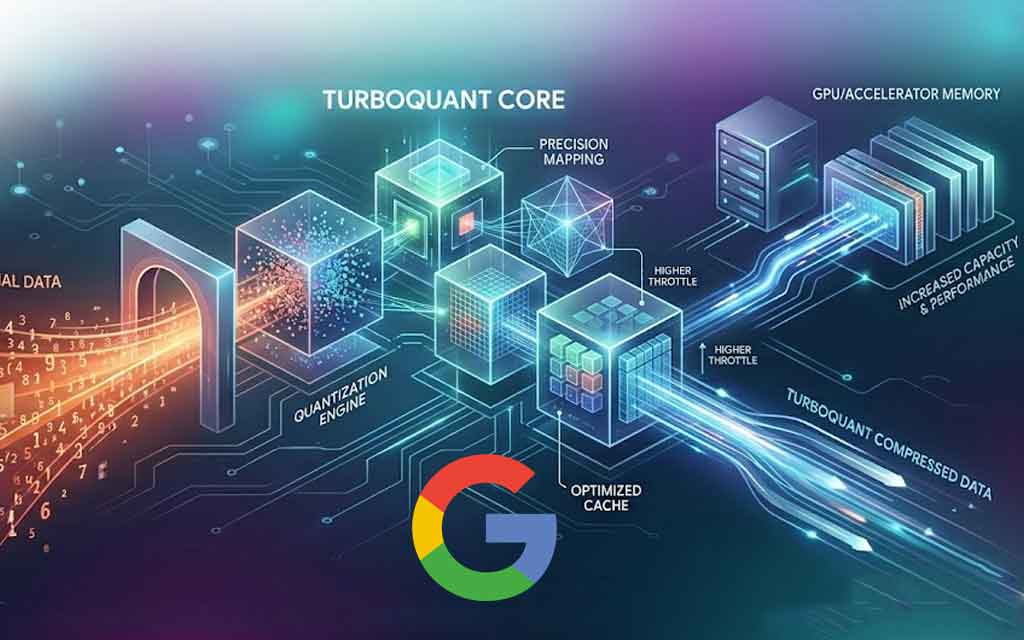
At the heart of the turmoil is TurboQuant, a training-free quantization algorithm suite from Google Research that targets the key-value (KV) cache—the high-speed “working memory” that stores past computations during AI inference to avoid redundant processing. Traditionally, this cache consumes massive amounts of high-bandwidth memory (HBM) and DRAM, especially in long-context tasks where models juggle vast amounts of conversational or contextual data.
TurboQuant achieves its feats through a clever two-step process combining PolarQuant and Quantized Johnson-Lindenstrauss (QJL):
- PolarQuant transforms high-dimensional vectors from Cartesian to polar coordinates (radius and angle), simplifying geometry and eliminating costly normalization steps while mapping data onto a compact circular grid.
- QJL then applies a 1-bit error-correction layer to preserve critical distances and relationships, ensuring perfect attention score accuracy.
The result? KV cache compression down to just 3 bits per value (from the standard 16-32 bits), delivering at least a 6x reduction in memory footprint and up to 8x faster computation of attention logits on Nvidia H100 GPUs. Benchmarks on models like Llama-3.1-8B, Gemma, and Mistral showed zero accuracy loss across rigorous long-context tests, including Needle-in-a-Haystack, LongBench, RULER, and vector search evaluations on datasets like GloVe.
Google Research scientists Amir Zandieh and Vahab Mirrokni described it as “redefining AI efficiency with extreme compression,” noting that it operates near theoretical lower bounds and enables longer context windows, faster inference, and more scalable semantic search—all via software alone.
The algorithm is detailed in a preprint (arXiv:2504.19874, slated for ICLR 2026) and builds on related techniques like PolarQuant (AISTATS 2026). While not yet open-sourced, its “theoretically grounded” nature suggests rapid adoption potential across the industry.
Market Carnage: Stocks Plummet as Fears of Oversupply Mount
The reaction was immediate and brutal:
- SK Hynix and Samsung Electronics (South Korea’s memory titans) each fell at least 5-6% in Seoul trading.
- Micron Technology (MU), Western Digital (WDC), SanDisk (SNDK), and Seagate (STX) dropped 3-8% in U.S. sessions, extending earlier losses.
- Japanese flash memory maker Kioxia shed nearly 6%.
These companies had been riding a massive AI-driven boom, with memory prices surging due to HBM shortages for GPUs powering models like those from OpenAI, Anthropic, and Google itself. Now, traders fear TurboQuant could ease that crunch by letting AI systems run with far less physical RAM—potentially flooding the market with excess supply and driving prices lower.
While no companies have yet issued formal quarterly loss reports tied directly to this (earnings cycles lag), the stock wipeout has already erased billions in collective market cap, with analysts warning of “million-dollar losses” in forward guidance if demand softens. One Seeking Alpha report noted early pressure on suppliers like MU, WDC, and SNDK.
Not All Doom and Gloom: Analysts See a “Buy the Dip” Opportunity
Many Wall Street voices are calling the sell-off an overreaction or classic profit-taking after months of explosive gains (Samsung and SK Hynix up over 50% YTD pre-announcement).
- SemiAnalysis analyst Ray Wang argued the KV cache is only 10-20% of total memory needs; reducing it could unlock more powerful models that ultimately demand higher overall hardware usage.
- Morgan Stanley’s Shawn Kim and Bank of America echoed this, invoking Jevons Paradox: Cheaper, faster AI inference will spur more usage, more complex applications, and greater long-term demand for DRAM, HBM, and storage.
- Wells Fargo’s Andrew Rocha noted it “attacks the cost curve” but doesn’t change AI capex trajectories—Google itself recently hiked 2026 spending projections dramatically.
Short-term RAM price forecasts remain upward for Q2/Q3 due to persistent supply constraints, but broader adoption of TurboQuant (or similar techniques) could exert downward pressure by late 2026, benefiting AI developers and end-users with cheaper cloud inference.
What This Means for the Future of AI and Computing
TurboQuant doesn’t solve training memory demands (which still require massive GPU clusters), but it supercharges inference—the phase where most real-world AI usage happens. Expect:
- Longer context windows in chatbots and agents without ballooning costs.
- More efficient on-device AI for smartphones and edge hardware.
- Lower barriers for startups and enterprises to deploy advanced models.
- Ripple effects in vector databases powering semantic search.
Google has positioned this as open research, potentially accelerating industry-wide efficiency gains. As one VentureBeat piece noted, it could cut enterprise AI costs by 50% or more.
The memory chip sector, long a cyclical rollercoaster, now faces a new variable: algorithmic disruption. While today’s panic reflects fears of a demand cliff, history shows efficiency breakthroughs often fuel bigger booms.
VFuture Media will continue monitoring earnings calls from Samsung, SK Hynix, Micron, and others in the coming weeks. Could this be the start of a software-led AI efficiency era—or just another buying opportunity for memory bulls? Stay tuned as the story unfolds.




Leave a Comment